· 5 min read
Saving $10k/month on Analytics - Snowplow Serverless Alternative
Faced with the high costs of traditional analytics solutions, our team implemented a serverless Snowplow alternative to dramatically reduce costs. By leveraging cloud-native technologies and serverless architectures, we not only achieved significant cost savings but also gained a scalable, flexible analytics platform with full data ownership.

The Evolution of Data Infrastructure
In recent years, the landscape of data tracking and analytics has undergone significant changes. While we previously advised against deploying custom tracking infrastructure, shifting market dynamics have led us to reconsider this stance.
Open Source
Given enough interest we’ll opensource our solution. Subscribe below to be notified of it.
The Org Bloat
Higher interest rates and reduced VC funding have forced SAAS providers like Segment, Rudderstack, mParticle, Amplitude and Snowplow to increase their prices. Many of these companies have developed top-heavy organizational structures, with over 60% of employees in non-engineering roles.
While solutions like PostHog may appear cost-effective initially, processing larger volumes of events (10M+ monthly) can quickly become expensive. Additionally, their data model often falls short when compared to more robust options like Snowplow.
We want to pay for reliably transforming HTTP requests into JSON and forwarding that into Snowflake, not for your overstaffed organisation.
Key Requirements for Modern Data Infrastructure
Our ideal data infrastructure solution must meet several critical criteria:
Data Ownership
The solution should be hosted in our cloud, ensuring data never leaves our environment.
Robust Data Model
We love Snowplow’s data model and schema based approach that validates every event, the ability to do codegen from schemas, large ecosystem of DBT code that significantly speeds up data wrangling and data analysis.
Scale to Zero and Infinity
The infrastructure should scale from zero to infinity, accommodating traffic spikes while keeping testing environment costs low.
Simple
While we have the expertise to deploy complex systems, we prioritize solutions that are simple to maintain and “just work”.
Cost-Effectiveness
From zero to 100M events per month, costs should be predictable, grow linearly, and remain affordable.
Current Infrastructure Overview
- Snowplow managed in our AWS account
- 20M to 50M events tracked per month
- Events forwarded to Snowflake and a couple of other destinations
- $7k to $10k monthly cost, significant part of which is Snowplow SAAS fee
While Snowplow has introduced cost-saving measures like the Streaming Loader, the biggest cost is the fees paid to Snowplow, not the infrastructure. And that makes it not viable for smaller organisations. Snowplow hosted solution is cheaper but still 10x the cost of our final solution.
Alternatives
After thorough evaluation, we’ve concluded that none of the available alternatives fully satisfy our requirements. Even if we were willing to compromise on some of our criteria, we would still face significant costs of at least $2k-$5k per month.
Our Solution
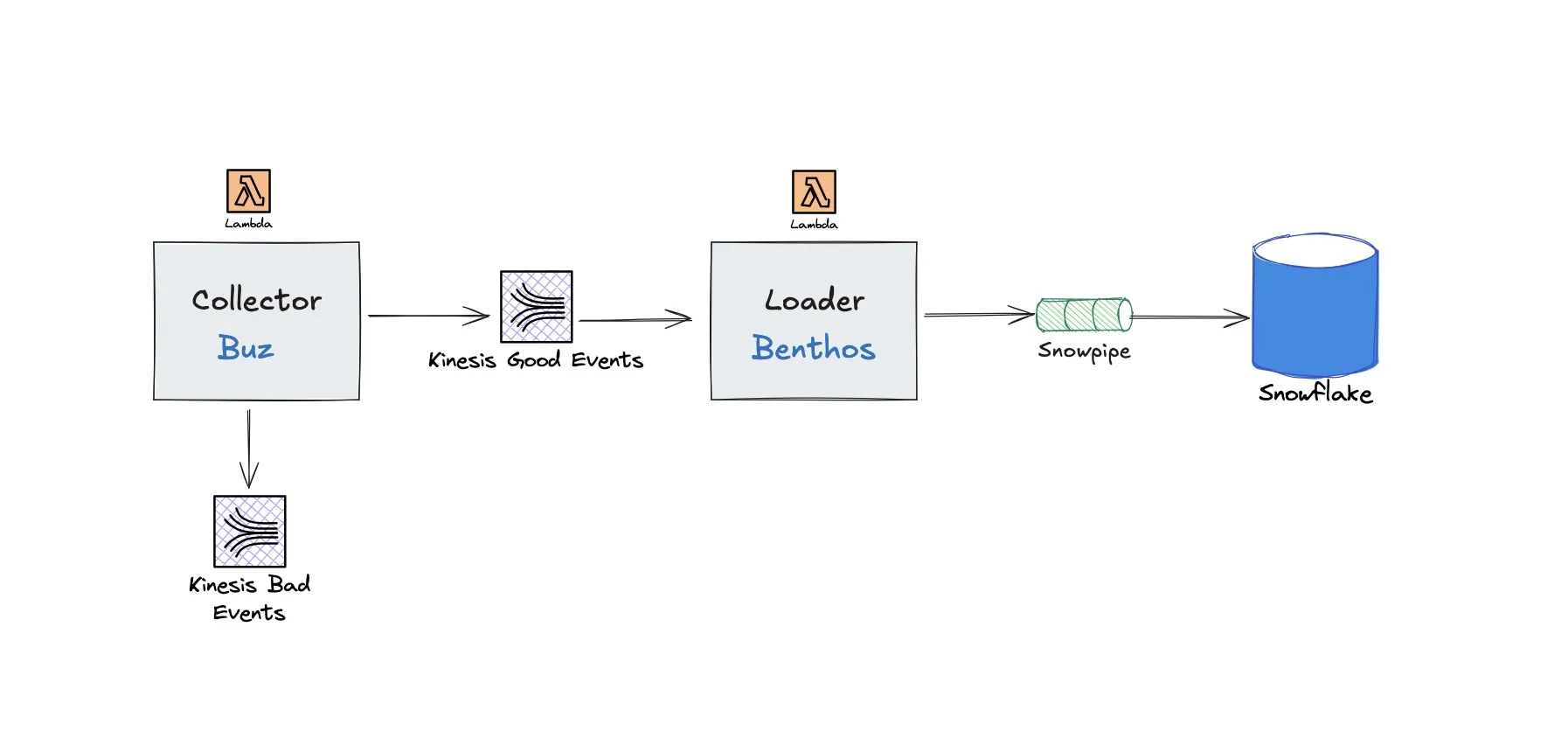
Collector
We initially were looking into writing our own collector, but serendipitously we came across Buz. It supports the Snowplow data model and schemas, so finding this fine piece of engineering tipped us over to actually doing this project. Instead of weeks or possibly months, this took a few days.
Had we implemented our own, we’d likely use Cloudflare to run the collector on the edge.
Stream
While both Buz and Benthos support many streaming technologies, we already use AWS for everything else so On Demand Kinesis made the most sense.
Loader
Another brilliant piece of enginnering for data movement and transformation was Benthos. With the recent Redpanda acqusition however, snowflake_put output was moved to Enterprise tier. Fortunately our friends at WarpStream forked it, so we use Bento.
While typically deployed as a long running process, Bento does support serverless deployment to Lambda.
Bento takes the events from Kinesis and stages files in a Snowflake stage, after that it calls Snowpipe to move the data into the final table.
This component works well, but we did need a bit of head scrathing to get it to work as needed.
In the future, when Snowflake releases SDK for Go or Python, we’d prefer to move this to use the Snowpipe Streaming which would make our data stack even simpler and cheaper.
Database
Most of our clients use Snowflake and a lot of our DBT code works on it, so this is an easy choice even for new projects.
We’re eager to put ClickHouse’s new JSON capabilities to the test. Depending on the results and specific project requirements, we may consider adopting it.
Automated Deployment with SST
The deployment process stands out as the most intricate aspect of our operation, involving multiple cloud platforms. We orchestrate deployments across Cloudflare, AWS, and Snowflake, which could potentially be a daunting task. However, we’ve streamlined this complexity by leveraging SST. It’s a crucial tool for simplifying and automating the entire deployment workflow.
It allows us to:
- Define our infrastructure as code
- Manage cross-platform deployments effortlessly
- Ensure consistency and reliability in our deployment process
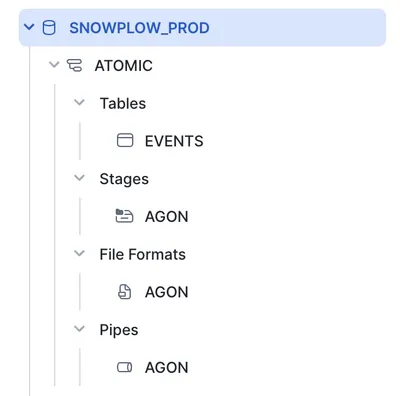
Schema Updates
When we modify the schema:
- A new version of the stack is released
- The system automatically detects schema changes
- Snowflake tables and Snowpipe are updated accordingly
Costs
While we haven’t received the final tally for the initial month, we’re confident the expense will remain below $100 per month. This certainly qualifies as a success in our books!
Reflections
Setting up this infrastructure demanded considerable effort, time investment and expertise. However, now that it’s operational, the cost savings are undeniable and substantial. While the long-term maintenance requirements are yet to be fully determined, we anticipate minimal ongoing upkeep. There’s a minimal risk new features would not be suported, but that’s very unlikely in our view.
We’re deeply appreciative of the open-source community behind Buz, Benthos, and SST. Their contributions have been invaluable, making the replication of a proprietary data pipeline surprisingly straightforward. The ease with which we accomplished this task is truly remarkable, showcasing the power of open-source collaboration.
The same approach can be taken to migrate off of Segment or Amplitude, without changing any tracking implementation, storing all events in the same format to Snowflake, ClickHouse or any other data warehouse.
Next Steps
We intend to further optimise this and potentially opensource one click install of our data stack. Stay tuned!
Our TODO includes:
- Better handling of bad events (we don’t really have them tbf)
- Test ClickHouse
- SQLMesh instead of DBT